When calculating common probabilities they will often include factorials which quickly explode. In a previous article I provided functions that help cancel some of the factorial expansion thus helping to keep the values within the limits of the NUMBER type.
The Hypergeometric Distribution is a mouthful of a name, but the idea is fairly easy to grasp. The distribution describes sequences of events that either succeed or fail, such as drawing a particular type of card from a standard deck of cards. The key feature is the sequence is without replacement. That is, once I’ve drawn a card from the deck I don’t put it back before drawing the next one. An example of using this distribution is calculating the odds of drawing exactly 4 Aces with a hand of 5 cards.
Given a population N, with S successes in the population, a sample size of R the probability of getting exactly X successes in the sample is:

Putting that into a function is pretty straightforward using the combination_cnt function defined in the earlier article.
CREATE OR REPLACE FUNCTION hgd(p_population IN INTEGER,
p_population_success IN INTEGER,
p_sample IN INTEGER,
p_sample_success IN INTEGER)
RETURN NUMBER
DETERMINISTIC
IS
n INTEGER := p_population;
s INTEGER := p_population_success;
r INTEGER := p_sample;
x INTEGER := p_sample_success;
-- Given population n
-- successes in population s
-- sample size r
-- successes in sample x
-- Returns the probability of getting exactly x successes.
--
--
-- C(s,x) C(n-s,r-x)
-- P(x) = -------------------
-- C(n,r)
--
--
--
BEGIN
RETURN combination_cnt(s, x)
* combination_cnt(n - s, r - x)
/ combination_cnt(n, r);
END hgd;
The odds of drawing all 4 aces in a hand of 5 cards is then:
select hgd(52,4,5,4) from dual;
0.00001846892603195124203527564872102687228738
While that did work well for this example, the multiplication of combinations could be large enough, with some inputs, to exceed the NUMBER type capacity. So, another option is to break the combination counts into its component factorials.

and after collapsing all of the fractions we get

That leaves 4 numerator values to multiply and 5 denominator values to multiply. Using factorial division we can cancel some of those values.
CREATE OR REPLACE FUNCTION hgd(p_population IN INTEGER,
p_population_success IN INTEGER,
p_sample IN INTEGER,
p_sample_success IN INTEGER)
RETURN NUMBER
DETERMINISTIC
IS
n INTEGER := p_population;
s INTEGER := p_population_success;
r INTEGER := p_sample;
x INTEGER := p_sample_success;
-- Given population n
-- successes in population s
-- sample size r
-- successes in sample x
-- Returns the probability of getting exactly x successes.
--
-- s! (n-s)!
-- ---------- ---------------------
-- C(s,x) C(n-s,r-x) (s-x)! x! ((n-s)-(r-x))! (r-x)!
-- P(x) = ------------------- = ------------------------------------
-- C(n,r) n!
-- ---------
-- (n-r)! r!
--
-- therefore...
--
-- s! (n-s)! (n-r)! r!
-- P(x) = ------------------------------------
-- (s-x)! x! ((n-s)-(r-x))! (r-x)! n!
--
BEGIN
RETURN factorial_division(s, s-x)
* factorial_division(n-s, x)
* factorial_division(n-r, (n-s)-(r-x))
* factorial_division(r, r-x)
/ factorial(n);
END hgd;
This yields
select hgd(52,4,5,4) from dual;
0.00001846892603195124203527564872102687228745
In mathematical notation the calculation is:

Simplifying we get:

That’s very close; but in fact, this change has made the calculation less accurate. Rearranging the divisions like this will help…
RETURN factorial_division(s, x)
* factorial_division(n-s, n)
* factorial_division(n-r, (n-s)-(r-x) )
* factorial_division(r, r-x)
/ factorial(s-x);
Simplifying we get:
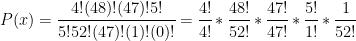
select hgd(52,4,5,4) from dual;
0.00001846892603195124203527564872102687228738
Of course, getting the correct result is desirable; but recompiling the function for each set of inputs trying to find the best combination of divisions is not a viable solution – especially since we will usually not already know what the most accurate result is.
However, if we’re willing to sacrifice a little performance we can increase the reliability of the function by extending the concept used in the factorial_division function. That is, instead of computing the full factorials, cancel as many of the factorials as possible before multiplying. This reduces the magnitudes of both numerator and denominator multiplications.
In addition to the cancellations I will also make a concession on input values. The examples to this point used relatively small numbers and the multiplications still quickly grew beyond the limits of the NUMBER data type. So, acknowledging that will always be a possibility I will impose an upper limit of the population size to be a NATURAL (0-2147483647.)
Calculations with populations approaching that limit can still encounter errors due to the multiplication or rounding in the division; but establishing that limit allows for other optimizations to help with calculations that are possible to compute accurately.
Knowing our inputs are constrained by NATURAL allows for construction of associative arrays indexed by NATURALs, where each position of the array is a count of the number of times that value appears in either the numerator or the denominator.
Using the previous values

Construct arrays of the numerator factorials and the denominator factorials. 0! and 1! will be excluded as they don’t change the multiplication result since they both evaluate to 1. Thus the numbers left for each arrray are:
Numerator (4!, 5!, 47!, 48!)
Denominator (4!, 47!, 52!)
Using associative arrays, we can build a numerator array with indexes, 4, 5, 47, 48 each having a count of 1, and a denominator array with indexes 4, 47, 52 each having a count of 1. If any of the input values or resulting subtractions caused a factorial to appear more than once the counts would be higher. For example, in the trivial case where we want to draw the entire deck. The probability of getting the entire deck are, obviously, 1.
Formally calculating it would be:

The resulting arrays would be a numerator array with index 52 having a count of 2. The denominator array would similarly have a single value at index 52, also with a count of 2.
With the factorials in the arrays the factorial division logic to cancel the factorials in descending order by index within each array.
So in the example above of drawing 4 of a kind with a hand of 5 cards the 48! is canceled by the 52! with 52, 51, 50, and 49 left over as denominator factors which are multiplied together.
47! in the numerator and denominator cancel completely. 4! is canceled by 5! leaving 5 in the numerator. 4! is left uncancelled in the numerator and multiplied with the 5.
Thus leaving a final calculation of

Implementing these changes in the HGD function yields:
CREATE OR REPLACE FUNCTION hgd(p_population IN NATURAL,
p_population_success IN NATURAL,
p_sample IN NATURAL,
p_sample_success IN NATURAL)
RETURN NUMBER
DETERMINISTIC
IS
n INTEGER := p_population;
s INTEGER := p_population_success;
r INTEGER := p_sample;
x INTEGER := p_sample_success;
-- Given population n
-- successes in population s
-- sample size r
-- successes in sample x
-- Returns the probability of getting exactly x successes.
--
-- s! (n-s)!
-- ---------- ---------------------
-- C(s,x) C(n-s,r-x) (s-x)! x! ((n-s)-(r-x))! (r-x)!
-- P(x) = ------------------- = ------------------------------------
-- C(n,r) n!
-- ---------
-- (n-r)! r!
--
-- therefore...
--
-- s! (n-s)! (n-r)! r!
-- P(x) = ------------------------------------
-- (s-x)! x! ((n-s)-(r-x))! (r-x)! n!
--
--
TYPE factor_array IS TABLE OF NATURAL
INDEX BY NATURAL;
v_numerator_product NUMBER := 1;
v_denominator_product NUMBER := 1;
v_numerator_factorials factor_array;
v_denominator_factorials factor_array;
v_nindex NATURAL;
v_dindex NATURAL;
PROCEDURE increment_factorial_count(p_array IN OUT factor_array,
p_index IN NATURAL)
IS
BEGIN
-- 0! and 1! both resolve to 1, so don't include them as a factor
IF p_index > 1
THEN
p_array(p_index) :=
CASE
WHEN p_array.EXISTS(p_index) THEN p_array(p_index) + 1
ELSE 1
END;
END IF;
END;
BEGIN
increment_factorial_count(v_numerator_factorials, s);
increment_factorial_count(v_numerator_factorials, n - s);
increment_factorial_count(v_numerator_factorials, n - r);
increment_factorial_count(v_numerator_factorials, r);
increment_factorial_count(v_denominator_factorials, s - x);
increment_factorial_count(v_denominator_factorials, x);
increment_factorial_count(v_denominator_factorials, (n - s) - (r - x));
increment_factorial_count(v_denominator_factorials, r - x);
increment_factorial_count(v_denominator_factorials, n);
v_nindex := v_numerator_factorials.LAST;
v_dindex := v_denominator_factorials.LAST;
WHILE v_nindex IS NOT NULL AND v_dindex IS NOT NULL
LOOP
CASE
WHEN v_nindex > v_dindex
THEN
-- If the numerator is greater than the denominator
-- then the denominator will be cancelled out
-- so, only multiply the elements of the factorial greater than the denominator
FOR i IN v_dindex + 1 .. v_nindex
LOOP
v_numerator_product := v_numerator_product * i;
END LOOP;
WHEN v_dindex > v_nindex
THEN
-- If the denominator is greater than the numerator
-- then the numerator will be cancelled out
-- so, only multiply the elements of the factorial greater than the numerator
FOR i IN v_nindex + 1 .. v_dindex
LOOP
v_denominator_product := v_denominator_product * i;
END LOOP;
ELSE
-- If n = d then n!=d! so they cancel completely with a quotient of 1
NULL;
END CASE;
-- After cancelling, decrement the count for indexes used.
-- If the count is 0, delete the index entirely.
CASE
WHEN v_numerator_factorials(v_nindex) > 1
THEN
v_numerator_factorials(v_nindex) :=
v_numerator_factorials(v_nindex) - 1;
ELSE
v_numerator_factorials.delete(v_nindex);
v_nindex := v_numerator_factorials.LAST;
END CASE;
CASE
WHEN v_denominator_factorials(v_dindex) > 1
THEN
v_denominator_factorials(v_dindex) :=
v_denominator_factorials(v_dindex) - 1;
ELSE
v_denominator_factorials.delete(v_dindex);
v_dindex := v_denominator_factorials.LAST;
END CASE;
END LOOP;
-- If after the cancelling there are still numerator elements left
-- then multiply those
WHILE v_nindex IS NOT NULL
LOOP
FOR i IN 1 .. v_numerator_factorials(v_nindex)
LOOP
v_numerator_product := v_numerator_product * factorial(v_nindex);
END LOOP;
v_numerator_factorials.delete(v_nindex);
v_nindex := v_numerator_factorials.LAST;
END LOOP;
-- If after the cancelling there are still denominator elements left
-- then multiply those
WHILE v_dindex IS NOT NULL
LOOP
FOR i IN 1 .. v_denominator_factorials(v_dindex)
LOOP
v_denominator_product :=
v_denominator_product * factorial(v_dindex);
END LOOP;
v_denominator_factorials.delete(v_dindex);
v_dindex := v_denominator_factorials.LAST;
END LOOP;
RETURN v_numerator_product / v_denominator_product;
END hgd;
And testing it out with the previous inputs, we get the expected result:
select hgd(52,4,5,4) from dual; 0.00001846892603195124203527564872102687228738
As mentioned earlier though, with large numbers it is possible to run into problems. Even with input values constrained to NATURAL limits, the intermediate multiplications can still grow beyond the limits of the NUMBER type.
Interestingly, when a large multiplication in SQL generates an overflow, an exception is raised. When the same multiplication happens in PL/SQL though, the result is an infinite value, represented as a tilde (~). The following example illustrates the two behaviors for the same values.
SQL> select 2000000000 * 5E+120 from dual;
select 2000000000 * 5E+120 from dual
*
ERROR at line 1:
ORA-01426: numeric overflow
SQL> begin
2 dbms_output.put_line(2000000000 * 5E+120);
3 end;
4 /
~
PL/SQL procedure successfully completed.
And this can be seen with the function too; also note the extended execution time for iterating through large numbers.
SQL> select hgd(2147483647,200000000,1000000000,4000000) from dual;
HGD(2147483647,200000000,1000000000,4000000)
--------------------------------------------
~
Elapsed: 00:00:27.15>
There are a few options for addressing this:
First and easiest, do nothing. There is a reasonable expectation of overflow for large values and letting it happen may not be an undesirable result. If this is the case for your data, then last version of the function above should be adequate for your needs.
Second, let overflows happen, but exit early. Once the intermediate calculations have overflowed, there’s no reason to keep churning. When a NUMBER overflows from one of the multiplications, the result will be a special 2-byte value (FF65). I could find no official documentation of this value; but it appears to be consistent across the last several releases of the Oracle database. Using this method, if any intermediate calculation for either the numerator or denominator products overflows, the loops exit and no further calculations are made. Since overflow math is not meaningful, I return NULL unless both values are valid. Some call the overflow value “infinity”. So there might be a temptation for try to return 0 or ~ values on the assumption it is infinite; but we know that can’t be true. Even if the input values cause the calculations to overflow, the result, whatever it would have been would still be finite. So, trying to return values as if it were infinite would be mathematically dubious.
CREATE OR REPLACE FUNCTION hgd2(p_population IN NATURAL,
p_population_success IN NATURAL,
p_sample IN NATURAL,
p_sample_success IN NATURAL)
RETURN NUMBER
DETERMINISTIC
IS
n INTEGER := p_population;
s INTEGER := p_population_success;
r INTEGER := p_sample;
x INTEGER := p_sample_success;
-- Given population n
-- successes in population s
-- sample size r
-- successes in sample x
-- Returns the probability of getting exactly x successes.
--
-- s! (n-s)!
-- ---------- ---------------------
-- C(s,x) C(n-s,r-x) (s-x)! x! ((n-s)-(r-x))! (r-x)!
-- P(x) = ------------------- = ------------------------------------
-- C(n,r) n!
-- ---------
-- (n-r)! r!
--
-- therefore...
--
-- s! (n-s)! (n-r)! r!
-- P(x) = ------------------------------------
-- (s-x)! x! ((n-s)-(r-x))! (r-x)! n!
--
--
TYPE factor_array IS TABLE OF NATURAL
INDEX BY NATURAL;
c_overflow CONSTANT NUMBER := UTL_RAW.cast_to_number(HEXTORAW('FF65'));
v_numerator_product NUMBER := 1;
v_denominator_product NUMBER := 1;
v_numerator_factorials factor_array;
v_denominator_factorials factor_array;
v_nindex NATURAL;
v_dindex NATURAL;
PROCEDURE increment_factorial_count(p_array IN OUT factor_array,
p_index IN NATURAL)
IS
BEGIN
-- 0! and 1! both resolve to 1, so don't include them as a factor
IF p_index > 1
THEN
p_array(p_index) :=
CASE
WHEN p_array.EXISTS(p_index) THEN p_array(p_index) + 1
ELSE 1
END;
END IF;
END;
BEGIN
increment_factorial_count(v_numerator_factorials, s);
increment_factorial_count(v_numerator_factorials, n - s);
increment_factorial_count(v_numerator_factorials, n - r);
increment_factorial_count(v_numerator_factorials, r);
increment_factorial_count(v_denominator_factorials, s - x);
increment_factorial_count(v_denominator_factorials, x);
increment_factorial_count(v_denominator_factorials, (n - s) - (r - x));
increment_factorial_count(v_denominator_factorials, r - x);
increment_factorial_count(v_denominator_factorials, n);
v_nindex := v_numerator_factorials.LAST;
v_dindex := v_denominator_factorials.LAST;
WHILE v_nindex IS NOT NULL
AND v_dindex IS NOT NULL
AND c_overflow != v_numerator_product
AND c_overflow != v_denominator_product
LOOP
CASE
WHEN v_nindex > v_dindex
THEN
-- If the numerator is greater than the denominator
-- then the denominator will be cancelled out
-- so, only multiply the elements of the factorial greater than the denominator
FOR i IN v_dindex + 1 .. v_nindex
LOOP
v_numerator_product := v_numerator_product * i;
IF v_numerator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
WHEN v_dindex > v_nindex
THEN
-- If the denominator is greater than the numerator
-- then the numerator will be cancelled out
-- so, only multiply the elements of the factorial greater than the numerator
FOR i IN v_nindex + 1 .. v_dindex
LOOP
v_denominator_product := v_denominator_product * i;
IF v_denominator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
ELSE
-- If n = d then n!=d! so they cancel completely with a quotient of 1
NULL;
END CASE;
-- If either numerator or denominator overflowed then quit trying to calculate further.
IF c_overflow IN (v_numerator_product, v_denominator_product)
THEN
EXIT;
END IF;
-- After cancelling, decrement the count for indexes used.
-- If the count is 0, delete the index entirely.
CASE
WHEN v_numerator_factorials(v_nindex) > 1
THEN
v_numerator_factorials(v_nindex) :=
v_numerator_factorials(v_nindex) - 1;
ELSE
v_numerator_factorials.delete(v_nindex);
v_nindex := v_numerator_factorials.LAST;
END CASE;
CASE
WHEN v_denominator_factorials(v_dindex) > 1
THEN
v_denominator_factorials(v_dindex) :=
v_denominator_factorials(v_dindex) - 1;
ELSE
v_denominator_factorials.delete(v_dindex);
v_dindex := v_denominator_factorials.LAST;
END CASE;
END LOOP;
-- If after the cancelling there are still numerator elements left
-- then multiply those. Keep going unless we overflow.
WHILE v_nindex IS NOT NULL
AND c_overflow NOT IN (v_numerator_product, v_denominator_product)
LOOP
FOR i IN 1 .. v_numerator_factorials(v_nindex)
LOOP
v_numerator_product := v_numerator_product * factorial(v_nindex);
IF v_numerator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
v_numerator_factorials.delete(v_nindex);
v_nindex := v_numerator_factorials.LAST;
END LOOP;
-- If after the cancelling there are still denominator elements left
-- then multiply those. Keep going unless we overflow.
WHILE v_dindex IS NOT NULL
AND c_overflow NOT IN (v_numerator_product, v_denominator_product)
LOOP
FOR i IN 1 .. v_denominator_factorials(v_dindex)
LOOP
v_denominator_product :=
v_denominator_product * factorial(v_dindex);
IF v_denominator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
v_denominator_factorials.delete(v_dindex);
v_dindex := v_denominator_factorials.LAST;
END LOOP;
RETURN CASE
WHEN c_overflow NOT IN
(v_numerator_product, v_denominator_product)
THEN
v_numerator_product / v_denominator_product
ELSE
NULL
END;
END hgd2;
This version works for smaller values as expected, but when an overflow happens it exits immediately.
SQL> select hgd2(52,4,5,4) from dual;
HGD2(52,4,5,4)
---------------------------------------------
.00001846892603195124203527564872102687228738
Elapsed: 00:00:00.00
SQL> select hgd2(2147483647,200000000,1000000000,4000000) from dual;
HGD2(2147483647,200000000,1000000000,4000000)
---------------------------------------------
~
Elapsed: 00:00:00.00
Another option would be to simply raise an overflow exception when one is detected. This would also result in immediate exit. Whether it is better functionality to return NULL or raise an exception, I’ll leave to your use case.
A version raising an exception follows:
CREATE OR REPLACE FUNCTION hgd3(p_population IN NATURAL,
p_population_success IN NATURAL,
p_sample IN NATURAL,
p_sample_success IN NATURAL)
RETURN NUMBER
DETERMINISTIC
IS
overflow_detected EXCEPTION;
PRAGMA EXCEPTION_INIT (overflow_detected, -1426);
n INTEGER := p_population;
s INTEGER := p_population_success;
r INTEGER := p_sample;
x INTEGER := p_sample_success;
-- Given population n
-- successes in population s
-- sample size r
-- successes in sample x
-- Returns the probability of getting exactly x successes.
--
-- s! (n-s)!
-- ---------- ---------------------
-- C(s,x) C(n-s,r-x) (s-x)! x! ((n-s)-(r-x))! (r-x)!
-- P(x) = ------------------- = ------------------------------------
-- C(n,r) n!
-- ---------
-- (n-r)! r!
--
-- therefore...
--
-- s! (n-s)! (n-r)! r!
-- P(x) = ------------------------------------
-- (s-x)! x! ((n-s)-(r-x))! (r-x)! n!
--
--
TYPE factor_array IS TABLE OF NATURAL
INDEX BY NATURAL;
c_overflow CONSTANT NUMBER := UTL_RAW.cast_to_number(HEXTORAW('FF65'));
v_numerator_product NUMBER := 1;
v_denominator_product NUMBER := 1;
v_numerator_factorials factor_array;
v_denominator_factorials factor_array;
v_nindex NATURAL;
v_dindex NATURAL;
PROCEDURE increment_factorial_count(p_array IN OUT factor_array,
p_index IN NATURAL)
IS
BEGIN
-- 0! and 1! both resolve to 1, so don't include them as a factor
IF p_index > 1
THEN
p_array(p_index) :=
CASE
WHEN p_array.EXISTS(p_index) THEN p_array(p_index) + 1
ELSE 1
END;
END IF;
END;
BEGIN
increment_factorial_count(v_numerator_factorials, s);
increment_factorial_count(v_numerator_factorials, n - s);
increment_factorial_count(v_numerator_factorials, n - r);
increment_factorial_count(v_numerator_factorials, r);
increment_factorial_count(v_denominator_factorials, s - x);
increment_factorial_count(v_denominator_factorials, x);
increment_factorial_count(v_denominator_factorials, (n - s) - (r - x));
increment_factorial_count(v_denominator_factorials, r - x);
increment_factorial_count(v_denominator_factorials, n);
v_nindex := v_numerator_factorials.LAST;
v_dindex := v_denominator_factorials.LAST;
WHILE v_nindex IS NOT NULL
AND v_dindex IS NOT NULL
AND c_overflow != v_numerator_product
AND c_overflow != v_denominator_product
LOOP
CASE
WHEN v_nindex > v_dindex
THEN
-- If the numerator is greater than the denominator
-- then the denominator will be cancelled out
-- so, only multiply the elements of the factorial greater than the denominator
FOR i IN v_dindex + 1 .. v_nindex
LOOP
v_numerator_product := v_numerator_product * i;
IF v_numerator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
WHEN v_dindex > v_nindex
THEN
-- If the denominator is greater than the numerator
-- then the numerator will be cancelled out
-- so, only multiply the elements of the factorial greater than the numerator
FOR i IN v_nindex + 1 .. v_dindex
LOOP
v_denominator_product := v_denominator_product * i;
IF v_denominator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
ELSE
-- If n = d then n!=d! so they cancel completely with a quotient of 1
NULL;
END CASE;
-- If either numerator or denominator overflowed then quit trying to calculate further.
IF c_overflow IN (v_numerator_product, v_denominator_product)
THEN
EXIT;
END IF;
-- After cancelling, decrement the count for indexes used.
-- If the count is 0, delete the index entirely.
CASE
WHEN v_numerator_factorials(v_nindex) > 1
THEN
v_numerator_factorials(v_nindex) :=
v_numerator_factorials(v_nindex) - 1;
ELSE
v_numerator_factorials.delete(v_nindex);
v_nindex := v_numerator_factorials.LAST;
END CASE;
CASE
WHEN v_denominator_factorials(v_dindex) > 1
THEN
v_denominator_factorials(v_dindex) :=
v_denominator_factorials(v_dindex) - 1;
ELSE
v_denominator_factorials.delete(v_dindex);
v_dindex := v_denominator_factorials.LAST;
END CASE;
END LOOP;
-- If after the cancelling there are still numerator elements left
-- then multiply those. Keep going unless we overflow.
WHILE v_nindex IS NOT NULL
AND c_overflow NOT IN (v_numerator_product, v_denominator_product)
LOOP
FOR i IN 1 .. v_numerator_factorials(v_nindex)
LOOP
v_numerator_product := v_numerator_product * factorial(v_nindex);
IF v_numerator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
v_numerator_factorials.delete(v_nindex);
v_nindex := v_numerator_factorials.LAST;
END LOOP;
-- If after the cancelling there are still denominator elements left
-- then multiply those. Keep going unless we overflow.
WHILE v_dindex IS NOT NULL
AND c_overflow NOT IN (v_numerator_product, v_denominator_product)
LOOP
FOR i IN 1 .. v_denominator_factorials(v_dindex)
LOOP
v_denominator_product :=
v_denominator_product * factorial(v_dindex);
IF v_denominator_product = c_overflow
THEN
EXIT;
END IF;
END LOOP;
v_denominator_factorials.delete(v_dindex);
v_dindex := v_denominator_factorials.LAST;
END LOOP;
IF c_overflow IN (v_numerator_product, v_denominator_product)
THEN
RAISE overflow_detected;
END IF;
RETURN CASE
WHEN c_overflow NOT IN
(v_numerator_product, v_denominator_product)
THEN
v_numerator_product / v_denominator_product
ELSE
NULL
END;
END hgd3;
And testing we get results for smaller values and the error for overflow as expected.
SQL> select hgd3(52,4,5,4) from dual;
HGD3(52,4,5,4)
--------------------------------------------------
.00001846892603195124203527564872102687228738
Elapsed: 00:00:00.00
SQL> select hgd3(2147483647,200000000,1000000000,4000000) from dual;
select hgd3(2147483647,200000000,1000000000,4000000) from dual
*
ERROR at line 1:
ORA-01426: numeric overflow
ORA-06512: at "SDS.HGD3", line 192
Elapsed: 00:00:00.01
Another option, which I’ll leave to the reader, would be to sacrifice precision and maintain intermediate calculations when an overflow or underflow would occur. That is, instead of calculating numerator product first then denominator, do them both on each iteration. If either value would overflow, then divide them, save the result and reset both products to 1 and continue. Each time you divide you will likely introduce some rounding error. Trying to reduce the number of divisions was one of the main features of the prior HGD, factorial_division, and combination_cnt functions. So pursuing this option, does run counter to the theme of trying to maximize accuracy. You’ll also have to watch if the intermediate calculation itself might overflow or underflow as you go.
Another problem with this option is you’ll be adding more calculations, so the large values which may iterate many millions of times just for the multiplications, you’ll have to add more checks for underflow/overflow and then add additional divisions and multiplications to maintain that intermediate value. Thus the function will be even slower for these larger inputs.
If you really need support for extreme precision of large values, I would suggest looking at mathematical libraries that specialize in that, possibly including arbitrary precision support.
Hopefully one of the forms above will be sufficient for you needs. For me they have been. Questions and comments, as always, are welcome.