Several years ago I needed to calculate the skewness of some data. That is, an indication of how asymmetric points are within a distribution. Unfortunately, I found there was no native feature to do this within SQL. So I wrote my own with the Oracle Data Cartridge Interface (ODCI.) Using ODCI you can create your own aggregate functions like MIN, MAX, and AVG.
Recently I had cause to revisit that function and thought I could do a little better. This also seemed like a good opportunity to share some of my work in tribute to Joel Kallman for all he gave to the Oracle community.
A happy discovery while looking into my old code – in the intervening years since my first implmentation Oracle had provided the SKEWNESS_SAMP function to their SQL implementation beginning with the 21c release.
Before I get into the doing things the hard way of implementing my own function, I’ll show the native way.
Here I’m calculating a small, known data set 1,2,4,8,16.
SQL> SELECT skewness_samp(n)
2 FROM ( SELECT POWER(2, LEVEL - 1) n
3 FROM DUAL
4* CONNECT BY LEVEL <= 5);
SKEWNESS_SAMP(N)
___________________________________________
1.32531470981340446231691036153849023328
Next I'll use dba_objects which has around100,000 objects in my test database. Your results will vary.
SQL> SELECT skewness_samp(object_id)
2* FROM dba_objects;
SKEWNESS_SAMP(OBJECT_ID)
___________________________________________
1.26477910446002342095053639554088606526
To implement my calculations, I'll be using the following formula:
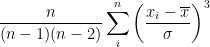
Where:
- n = number of elements in the sample
= the ith element within the sample (Sum where i=1 to n)
= the mean of the sample
= the standard deviation of the sample
So, using the same data as above, we can test this formula.
SQL> WITH sample_data AS
2 (SELECT POWER(2, LEVEL - 1) n
3 FROM DUAL
4 CONNECT BY LEVEL <= 5)
5 SELECT SUM(z) skewness
6 FROM (SELECT COUNT(*) OVER()
7 / (COUNT(*) OVER() - 1)
8 / (COUNT(*) OVER() - 2)
9 * POWER((n - AVG(n) OVER()) / STDDEV(n) OVER(), 3) z
10* FROM sample_data);
SKEWNESS
___________________________________________
1.32531470981340493277036905772942591043
So, it's not exactly the same as the native function, but differing only after 15 decimal places I think it's safe to say it's a limitation of internal rounding errors.
Using this logic we can build a function to iterate on a collection, such as an already aggregated set of values. With my function I'll have it return null and 0 for data sets of 0, 1, or 2 values.
CREATE OR REPLACE FUNCTION numtabskewness(p_nums IN numtab)
RETURN NUMBER
IS
v_result NUMBER;
v_count INTEGER := p_nums.COUNT;
BEGIN
-- Implement the formula
-- n/((n-1)(n-2)) SUM((x(i) - m)/s)^3
--
-- Where:
-- n = number of elements in the sample
-- x(i) = the ith element with the sample (Sum where i=1..n)
-- m = the mean of the sample
-- s = the standard deviation of the sample
CASE v_count
WHEN 0
THEN
v_result := NULL;
WHEN 1
THEN
v_result := 0;
WHEN 2
THEN
v_result := 0;
ELSE
SELECT SUM(z)
INTO v_result
FROM (SELECT v_count
/ (v_count - 1)
/ (v_count - 2)
* POWER(
(COLUMN_VALUE - AVG(COLUMN_VALUE) OVER())
/ STDDEV(COLUMN_VALUE) OVER(),
3) z
FROM TABLE(p_nums));
END CASE;
RETURN v_result;
END;
Where numtab is a simple nested table collection:
CREATE OR REPLACE TYPE numtab IS TABLE OF NUMBER;
Using it is simply getting a collection and passing it to the function.
SQL> SELECT numtabskewness(nums)
FROM (SELECT numtab(1, 2, 4, 8, 16) nums FROM DUAL);
NUMTABSKEWNESS(NUMS)
___________________________________________
1.32531470981340493277036905772942591043
SQL> SELECT numtabskewness(CAST(COLLECT(object_id) AS numtab)) FROM dba_objects;
NUMTABSKEWNESS(CAST(COLLECT(OBJECT_ID)ASNUMTAB))
___________________________________________________
1.26477910446002362104514032748246287218
That works, but seems kind of inefficient to use sql within the pl/sql to do the calculation. We can iterate directly on the collection itself.
CREATE OR REPLACE FUNCTION sds.numtabskewness2(p_nums IN numtab)
RETURN NUMBER
IS
v_variance NUMBER := 0;
v_stddev NUMBER;
v_mean NUMBER := 0;
v_temp NUMBER := 0;
v_count INTEGER := p_nums.COUNT;
v_result NUMBER;
BEGIN
-- Implement the formula
-- n/((n-1)(n-2)) SUM((x(i) - m)/s)^3
--
-- Where:
-- n = number of elements in the sample
-- x(i) = the ith element with the sample (Sum where i=1..n)
-- m = the mean of the sample
-- s = the standard deviation of the sample
CASE v_count
WHEN 0
THEN
v_result := NULL;
WHEN 1
THEN
v_result := 0;
WHEN 2
THEN
v_result := 0;
ELSE
-- Calculate the mean from the total and count
FOR i IN 1 .. v_count
LOOP
v_mean := v_mean + p_nums(i);
END LOOP;
v_mean := v_mean / v_count;
-- calculate the variance by iterating through all of the values again
FOR i IN 1 .. v_count
LOOP
v_variance := v_variance + ((p_nums(i) - v_mean) ** 2);
END LOOP;
v_variance := v_variance / (v_count-1);
-- Standard deviation of population = square root of variance
v_stddev := SQRT(v_variance);
-- Sum the cube of the difference from mean divided by standard deviation
FOR i IN 1 .. v_count
LOOP
v_temp := v_temp + POWER((p_nums(i) - v_mean) / v_stddev, 3);
END LOOP;
-- apply count factoring against the sum
v_result := v_count / (v_count - 1) / (v_count - 2) * v_temp;
END CASE;
RETURN v_result;
END;
/
Testing the function on the same sample data used previously, note the calculated value is very similar to but not exactly the same as the previous version for a large sample. Again, something small in the internal rounding; but this time only after 37 decimal places.
SQL> SELECT numtabskewness2(nums)
FROM (SELECT numtab(1, 2, 4, 8, 16) nums FROM DUAL);
NUMTABSKEWNESS2(NUMS)
___________________________________________
1.32531470981340493277036905772942591043
SQL> SELECT numtabskewness2(CAST(COLLECT(object_id) AS numtab)) FROM dba_objects;
NUMTABSKEWNESS(CAST(COLLECT(OBJECT_ID)ASNUMTAB))
___________________________________________________
1.26477910446002362104514032748246287204
These work as long as we already have an aggregated collection, but it would be simpler to just call an aggregate directly. This is how I chose to implement my original function, using the ODCI syntax. Using this user-defined aggregate we can invoke it with a simple:
SELECT skewness(x) FROM sample_data;
Unfortunately, we can't use native aggregate results within our user-defined aggregate. So, we'll have to generate the count, mean, and standard deviation ourselves. To that end, we'll keep a running count and total along with the actual values as we go.
CREATE OR REPLACE TYPE skewness_agg_type AS OBJECT
(
v_values numtab,
STATIC FUNCTION odciaggregateinitialize(ctx IN OUT skewness_agg_type)
RETURN NUMBER,
MEMBER FUNCTION odciaggregateiterate(self IN OUT skewness_agg_type,
p_value IN NUMBER)
RETURN NUMBER,
MEMBER FUNCTION odciaggregatemerge(self IN OUT skewness_agg_type,
ctx2 IN skewness_agg_type)
RETURN NUMBER,
MEMBER FUNCTION odciaggregateterminate(self IN skewness_agg_type,
returnvalue OUT NUMBER,
flags IN NUMBER)
RETURN NUMBER
);
/
CREATE OR REPLACE TYPE BODY skewness_agg_type
IS
STATIC FUNCTION odciaggregateinitialize(ctx IN OUT skewness_agg_type)
RETURN NUMBER
IS
BEGIN
-- Initialize to an empty collection
ctx := skewness_agg_type(numtab());
RETURN odciconst.success;
END odciaggregateinitialize;
MEMBER FUNCTION odciaggregateiterate(self IN OUT skewness_agg_type,
p_value IN NUMBER)
RETURN NUMBER
IS
BEGIN
-- For each new value,
-- add the value to our collection
self.v_values.EXTEND;
self.v_values(self.v_values.COUNT) := p_value;
RETURN odciconst.success;
END odciaggregateiterate;
MEMBER FUNCTION odciaggregatemerge(self IN OUT skewness_agg_type,
ctx2 IN skewness_agg_type)
RETURN NUMBER
IS
BEGIN
-- If merging two sub-results (possibly from parallel threads)
-- The collection should hold all values from both intermediate results
self.v_values := self.v_values MULTISET UNION ALL ctx2.v_values;
RETURN odciconst.success;
END odciaggregatemerge;
MEMBER FUNCTION odciaggregateterminate(self IN skewness_agg_type,
returnvalue OUT NUMBER,
flags IN NUMBER)
RETURN NUMBER
IS
v_count INTEGER := self.v_values.COUNT;
BEGIN
-- Implement the formula
-- n/((n-1)(n-2)) SUM((x(i) - m)/s)^3
--
-- Where:
-- n = number of elements in the sample
-- x(i) = the ith element with the sample (Sum where i=1..n)
-- m = the mean of the sample
-- s = the standard deviation of the sample
SELECT SUM(z)
INTO returnvalue
FROM (SELECT v_count
/ (v_count - 1)
/ (v_count - 2)
* POWER(
(COLUMN_VALUE - AVG(COLUMN_VALUE) OVER())
/ STDDEV(COLUMN_VALUE) OVER(),
3) z
FROM TABLE(self.v_values));
RETURN odciconst.success;
END odciaggregateterminate;
END;
/
CREATE OR REPLACE FUNCTION skewness(p_value NUMBER)
RETURN NUMBER
PARALLEL_ENABLE
AGGREGATE USING skewness_agg_type;
/
Now we have an aggregate function we can test it with the same sample data above and should get the same result.
SQL> SELECT skewness(n)
2 FROM ( SELECT POWER(2, LEVEL - 1) n
3 FROM DUAL
4 CONNECT BY LEVEL <= 5);
SKEWNESS(N)
___________________________________________
1.32531470981340493277036905772942591043
SQL> SELECT skewness(object_id)
2 FROM dba_objects;
SKEWNESS(OBJECT_ID)
___________________________________________
1.26477910446002362104514032748246287218
As expected, the terminating member function using the SQL-based approach returns the same results as the SQL results shown above. Rewriting the terminator to iterate across the collection with pl/sql, will return those results. Below I've only listed the terminate function, the rest of the object body is the same as above.
MEMBER FUNCTION odciaggregateterminate(self IN skewness_agg_type,
returnvalue OUT NUMBER,
flags IN NUMBER)
RETURN NUMBER
IS
v_variance NUMBER := 0;
v_stddev NUMBER;
v_mean NUMBER := 0;
v_temp NUMBER := 0;
v_count INTEGER := v_values.COUNT;
BEGIN
-- Implement the formula
-- n/((n-1)(n-2)) SUM((x(i) - m)/s)^3
--
-- Where:
-- n = number of elements in the sample
-- x(i) = the ith element with the sample (Sum where i=1..n)
-- m = the mean of the sample
-- s = the standard deviation of the sample
CASE v_count
WHEN 0
THEN
returnvalue := NULL;
WHEN 1
THEN
returnvalue := 0;
WHEN 2
THEN
returnvalue := 0;
ELSE
-- Calculate the mean from the total and count
FOR i IN 1 .. v_count
LOOP
v_mean := v_mean + v_values(i);
END LOOP;
v_mean := v_mean / v_count;
-- Calculate the variance by iterating through all of the values
FOR i IN 1 .. v_count
LOOP
v_variance := v_variance + ((v_values(i) - v_mean) ** 2);
END LOOP;
v_variance := v_variance / (v_count-1);
-- Standard deviation = square root of variance
v_stddev := SQRT(v_variance);
-- Sum the cube of the difference from mean divided by standard deviation
FOR i IN 1 .. v_count
LOOP
v_temp :=
v_temp + POWER((v_values(i) - v_mean) / v_stddev, 3);
END LOOP;
-- apply count factoring against the sum
returnvalue := v_count / (v_count - 1) / (v_count - 2) * v_temp;
END CASE;
RETURN odciconst.success;
END odciaggregateterminate;
As expected, the results are the same as the previous pl/sql-based iteration.
SQL> SELECT skewness(n)
2 FROM ( SELECT POWER(2, LEVEL - 1) n
3 FROM DUAL
4 CONNECT BY LEVEL <= 5);
SKEWNESS(N)
___________________________________________
1.32531470981340493277036905772942591043
SQL> SELECT skewness(object_id)
2 FROM dba_objects;
SKEWNESS(OBJECT_ID)
___________________________________________
1.26477910446002362104514032748246287204
If you are unfamiliar with the ODCI syntax, the constructs above may appear overly complex; but they are actually fairly easy to use.
Each aggregate needs 4 parts
- initializer - this is the method invoked by the function before processing any rows. It sets up initial values, in this case an empty collection.
- iterator - This method is invoked once for each row processed. For this example, it appends the new value to the stored collection.
- merge - this method might not be called but is necessary to ensure proper processing of sub-results. The most common reason to encounter these would be parallel queries where 2 threads each process some subset of the data and the PQ coordinator must merge the results into a single total result
- terminator - this method is invoked after the last row is processed and a final result needs to be returned
If you have 21c or later then I recommend using the native functions over these manual methods, but if you have an older version or if you need to adjust the implementation to accommodate your own rounding rules, I hope these examples provide a useful framework to build on.