After completing my article about skewness of a sample for Joel Kallman Day I decided I could do one more and write up the related functionality for skewness of a population.
Like skewness of a sample, the purpose of the function is to indicate the degree and direction of asymmetry in a data distribution. Like the SKEWNESS_SAMP function in my previous article, the 21c release of the database includes the SKEWNESS_POP aggregate.
The usage is similar and here I’ll compare the results of the population vs sample skewness. Here I’m calculating a small, known data set 1,2,4,8,16.
SQL> select skewness_pop(n), skewness_samp(n) from
2 (select power(2,level-1) n from dual connect by level <= 5);
SKEWNESS_POP(N) SKEWNESS_SAMP(N)
____________________ ___________________________________________
0.889048134816954 1.32531470981340446231691036153849023328
For a small sample like this, the difference in skew can be quite large . For larger samples, the two values will tend to grow closer together. Using dba_objects as my data population with about 100 thousand rows, the results are beginning to converge.
SQL> select skewness_pop(object_id), skewness_samp(object_id)
2 from dba_objects;
SKEWNESS_POP(OBJECT_ID) SKEWNESS_SAMP(OBJECT_ID)
__________________________ ___________________________________________
1.264888176352768 1.26490775402173997059265535485057799779
To implement my calculations, I'll be using the following formula:
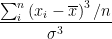
Where:
- n = number of data points in the population
= the ith element of the population (Sum where i=1 to n)
= the mean of the population
= the standard deviation of the population
So, using the same data as above, we can test this formula and see we come up with similar results to the native function.
SQL> WITH
2 sample_data
3 AS
4 ( SELECT POWER(2, LEVEL - 1) n
5 FROM DUAL
6 CONNECT BY LEVEL <= 5)
7 SELECT SUM(z) / cnt / POWER(sigma, 3) skewness
8 FROM (SELECT POWER(n - AVG(n) OVER(), 3) z,
9 COUNT(*) OVER() cnt,
10 STDDEV_POP(n) OVER() sigma
11 FROM sample_data)
12 GROUP BY cnt, sigma;
SKEWNESS
____________________________________________
0.889048134816954315589774168371754332528
Using this logic we can build a function to iterate on a collection, such as an already aggregated set of values. With my function I'll have it return null and 0 for data sets of 0, 1, or 2 values, just as the native function does.
CREATE OR REPLACE FUNCTION numtab_population_skewness(p_nums IN numtab)
RETURN NUMBER
IS
v_variance NUMBER := 0;
v_stddev NUMBER;
v_mean NUMBER := 0;
v_temp NUMBER := 0;
v_count INTEGER := p_nums.COUNT;
v_result NUMBER;
BEGIN
-- Implement the formula
-- sum((x(i)-m)^3) / n / (s^3)
--
-- Where:
-- n = number of data points in the population
-- x(i) = the ith element of the sample (Sum where i=1..n)
-- m = the mean of the population
-- s = the standard deviation of the population
CASE v_count
WHEN 0
THEN
v_result := NULL;
WHEN 1
THEN
v_result := 0;
WHEN 2
THEN
v_result := 0;
ELSE
-- Calculate the mean from the total and count
FOR i IN 1 .. v_count
LOOP
v_mean := v_mean + p_nums(i);
END LOOP;
v_mean := v_mean / v_count;
-- Standard deviation of population = square root of (variance/(N))
-- So, first step is calculate the variance by iterating through all of the values
FOR i IN 1 .. v_count
LOOP
v_variance := v_variance + ((p_nums(i) - v_mean) ** 2);
END LOOP;
v_stddev := SQRT(v_variance / v_count);
-- Sum the cube of the difference from mean divided by standard deviation
FOR i IN 1 .. v_count
LOOP
v_temp := v_temp + (p_nums(i) - v_mean) ** 3;
END LOOP;
v_result := v_temp / v_count / (v_stddev ** 3);
END CASE;
RETURN v_result;
END;
/
Where numtab is a simple nested table collection as used in the previous article:
CREATE OR REPLACE TYPE numtab IS TABLE OF NUMBER;
Using it is simply getting a collection and passing it to the function.
SQL> SELECT numtab_population_skewness(nums)
2 FROM (SELECT numtab(1, 2, 4, 8, 16) nums FROM DUAL);
NUMTAB_POPULATION_SKEWNESS(NUMS)
____________________________________________
0.889048134816954315589774168371754332528
That works, but as with calculating skewness of samples, it will be easier if we can call the aggregate directly on a column of values. So we'll create a user-defined aggregate with the ODCI syntax using similar logic.
CREATE OR REPLACE TYPE skewness_pop_agg_type AS OBJECT
(
v_values numtab,
STATIC FUNCTION odciaggregateinitialize(ctx IN OUT skewness_pop_agg_type)
RETURN NUMBER,
MEMBER FUNCTION odciaggregateiterate(self IN OUT skewness_pop_agg_type,
p_value IN NUMBER)
RETURN NUMBER,
MEMBER FUNCTION odciaggregatemerge(self IN OUT skewness_pop_agg_type,
ctx2 IN skewness_pop_agg_type)
RETURN NUMBER,
MEMBER FUNCTION odciaggregateterminate(self IN skewness_pop_agg_type,
returnvalue OUT NUMBER,
flags IN NUMBER)
RETURN NUMBER
);
/
CREATE OR REPLACE TYPE BODY skewness_pop_agg_type
IS
STATIC FUNCTION odciaggregateinitialize(ctx IN OUT skewness_pop_agg_type)
RETURN NUMBER
IS
BEGIN
-- Initialize to an empty collection
ctx := skewness_pop_agg_type(numtab());
RETURN odciconst.success;
END odciaggregateinitialize;
MEMBER FUNCTION odciaggregateiterate(self IN OUT skewness_pop_agg_type,
p_value IN NUMBER)
RETURN NUMBER
IS
BEGIN
-- For each new value,
-- add the value to our collection
self.v_values.EXTEND;
self.v_values(self.v_values.COUNT) := p_value;
RETURN odciconst.success;
END odciaggregateiterate;
MEMBER FUNCTION odciaggregatemerge(self IN OUT skewness_pop_agg_type,
ctx2 IN skewness_pop_agg_type)
RETURN NUMBER
IS
BEGIN
-- If merging two sub-results (possibly from parallel threads)
-- The collection should hold all values from both intermediate results
self.v_values := self.v_values MULTISET UNION ALL ctx2.v_values;
RETURN odciconst.success;
END odciaggregatemerge;
MEMBER FUNCTION odciaggregateterminate(self IN skewness_pop_agg_type,
returnvalue OUT NUMBER,
flags IN NUMBER)
RETURN NUMBER
IS
v_variance NUMBER := 0;
v_stddev NUMBER;
v_mean NUMBER := 0;
v_temp NUMBER := 0;
v_count INTEGER := v_values.COUNT;
v_result NUMBER;
BEGIN
-- Implement the formula
-- sum((x(i)-m)^3) / n / (s^3)
--
-- Where:
-- n = number of data points in the population
-- x(i) = the ith element of the sample (Sum where i=1..n)
-- m = the mean of the population
-- s = the standard deviation of the population
CASE v_count
WHEN 0
THEN
v_result := NULL;
WHEN 1
THEN
v_result := 0;
WHEN 2
THEN
v_result := 0;
ELSE
-- Calculate the mean from the total and count
FOR i IN 1 .. v_count
LOOP
v_mean := v_mean + v_values(i);
END LOOP;
v_mean := v_mean / v_count;
-- Standard deviation of population = square root of variance
-- So, first step is calculate the variance by iterating through all of the values again
FOR i IN 1 .. v_count
LOOP
v_variance := v_variance + ((v_values(i) - v_mean) ** 2);
END LOOP;
v_variance := v_variance / v_count;
v_stddev := SQRT(v_variance);
-- Sum the cube of the difference from mean
FOR i IN 1 .. v_count
LOOP
v_temp := v_temp + (v_values(i) - v_mean) ** 3;
END LOOP;
returnvalue := v_temp / v_count / (v_stddev ** 3);
END CASE;
RETURN odciconst.success;
END odciaggregateterminate;
END;
/
CREATE OR REPLACE FUNCTION population_skewness(p_value NUMBER)
RETURN NUMBER
PARALLEL_ENABLE
AGGREGATE USING skewness_pop_agg_type;
/
Now we have an aggregate function we can test it against the native function to see how it compares.
SQL> SELECT skewness_pop(n), population_skewness(n)
2 FROM ( SELECT POWER(2, LEVEL - 1) n
3 FROM DUAL
4 CONNECT BY LEVEL <= 5);
SKEWNESS_POP(N) POPULATION_SKEWNESS(N)
____________________ ____________________________________________
0.889048134816954 0.889048134816954315589774168371754332528
SQL> SELECT skewness_pop(object_id), population_skewness(object_id)
2 FROM dba_objects;
SKEWNESS_POP(OBJECT_ID) POPULATION_SKEWNESS(OBJECT_ID)
__________________________ _________________________________________
1.265078306594029 1.265078306594028618334920641985970805
This looks pretty good.
As with the ODCI function I created for the samples, I recommend using the native function instead of the manual approach, provided you are on 21c or higher. But, if you have an older version where these functions aren't available yet, then using ODCI or the function over a collection above will allow you to calculate the values yourself.
Also, you can see the native function returns results with less precision than the manual calculations. This is, undoubtedly a way to deal with rounding errors at higher precision. If this is unacceptable, then using the pl/sql frameworks above may help you achieve greater precision in your results; but be careful as they are still subject to the precision limitations of the native functions used in the intermediate calculations.
I know skewness calculations aren't often the most pressing of concerns in database development, but they are another tool in your toolbox for better understanding your data. I hope this helps and thank you for reading. Questions, as always, are welcome.